A closed loop: Proposer → Evaluator → Memory
A Proposer evolves solutions and writes tasks; an Evaluator validates and measures empirical difficulty; a Memory module feeds accepted lineages and past failures back into search — turning repeated sampling into adaptive evolution.

Proposer
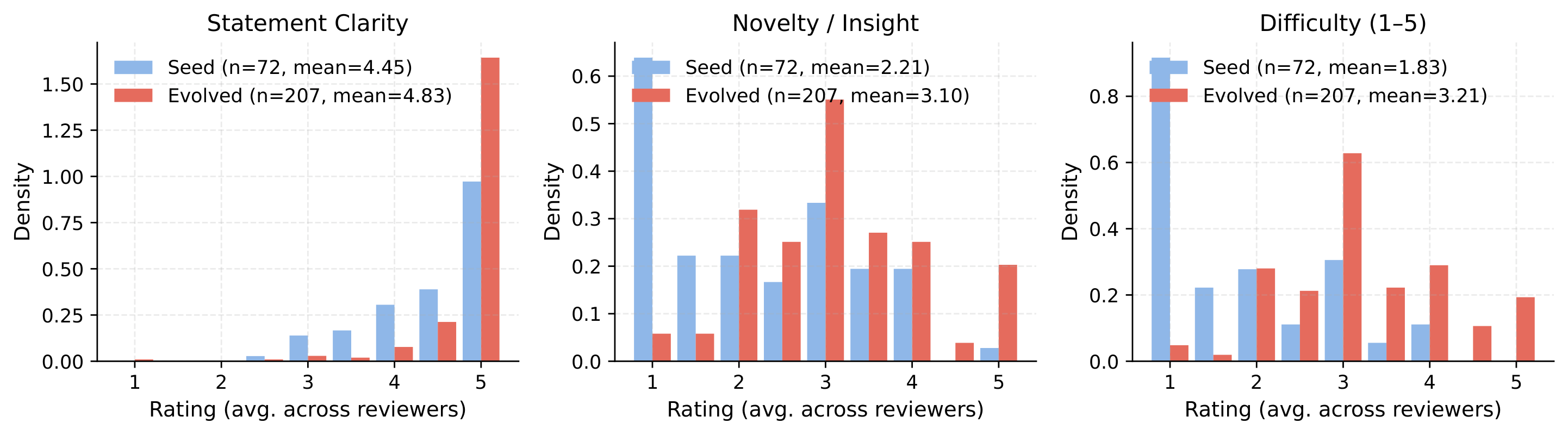
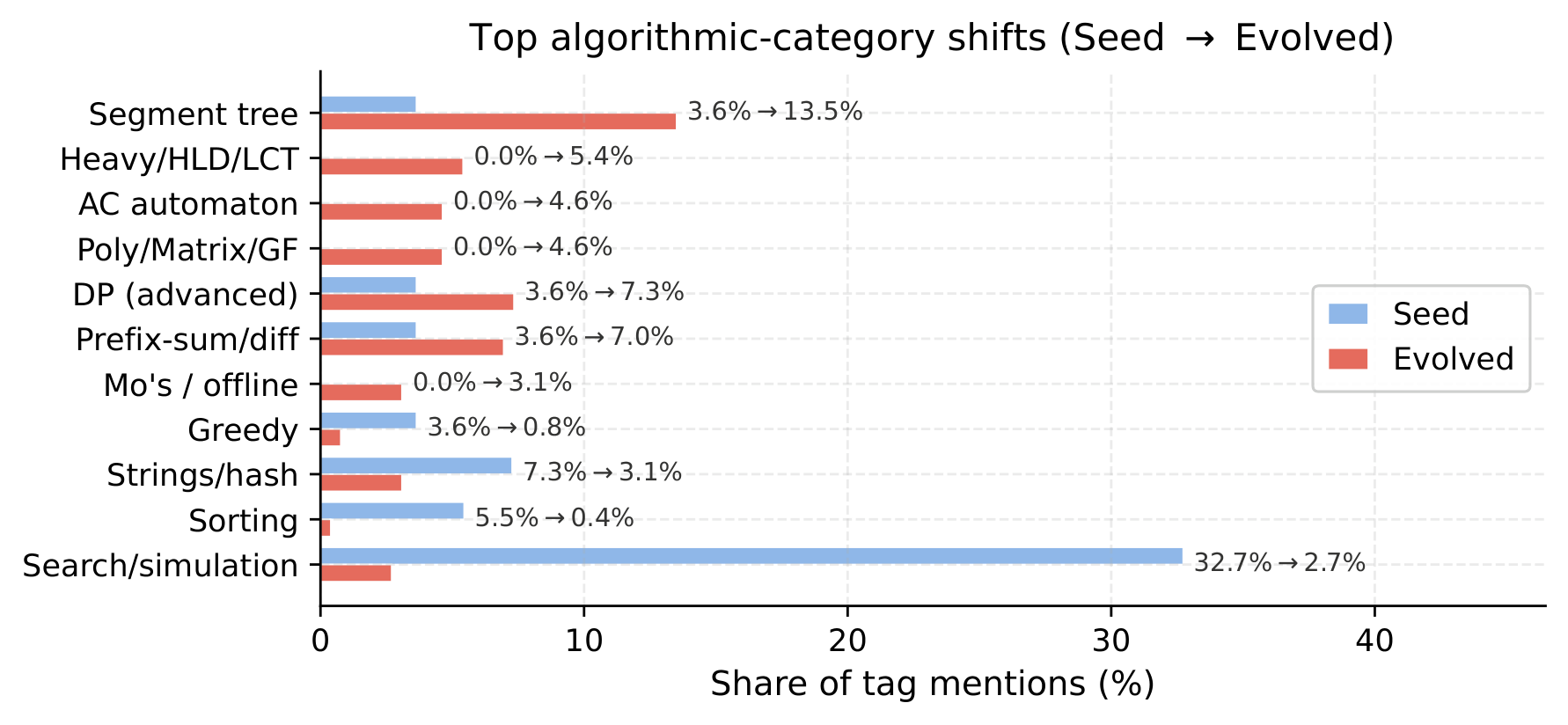
Mutates the parent solution into a structurally different one, then derives a natural statement, public examples, and tiered hidden tests — all anchored by executing the evolved reference.
Evaluator
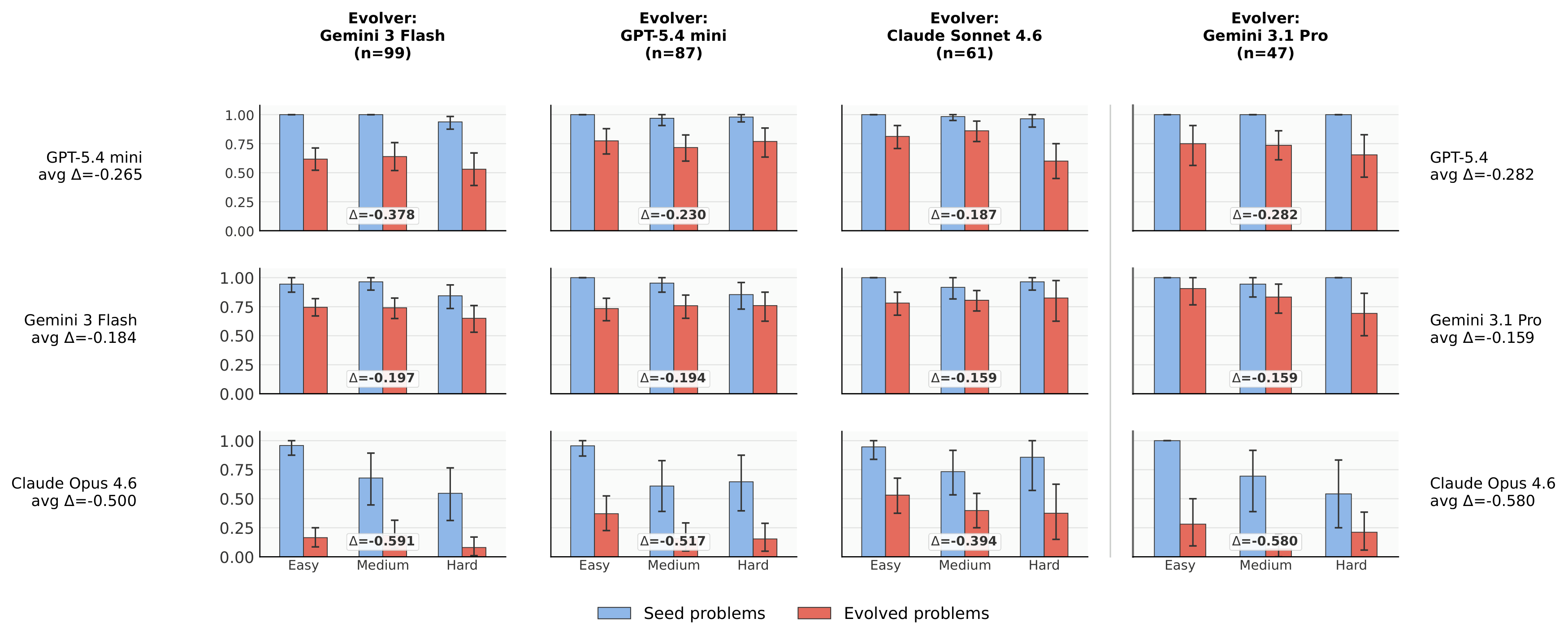
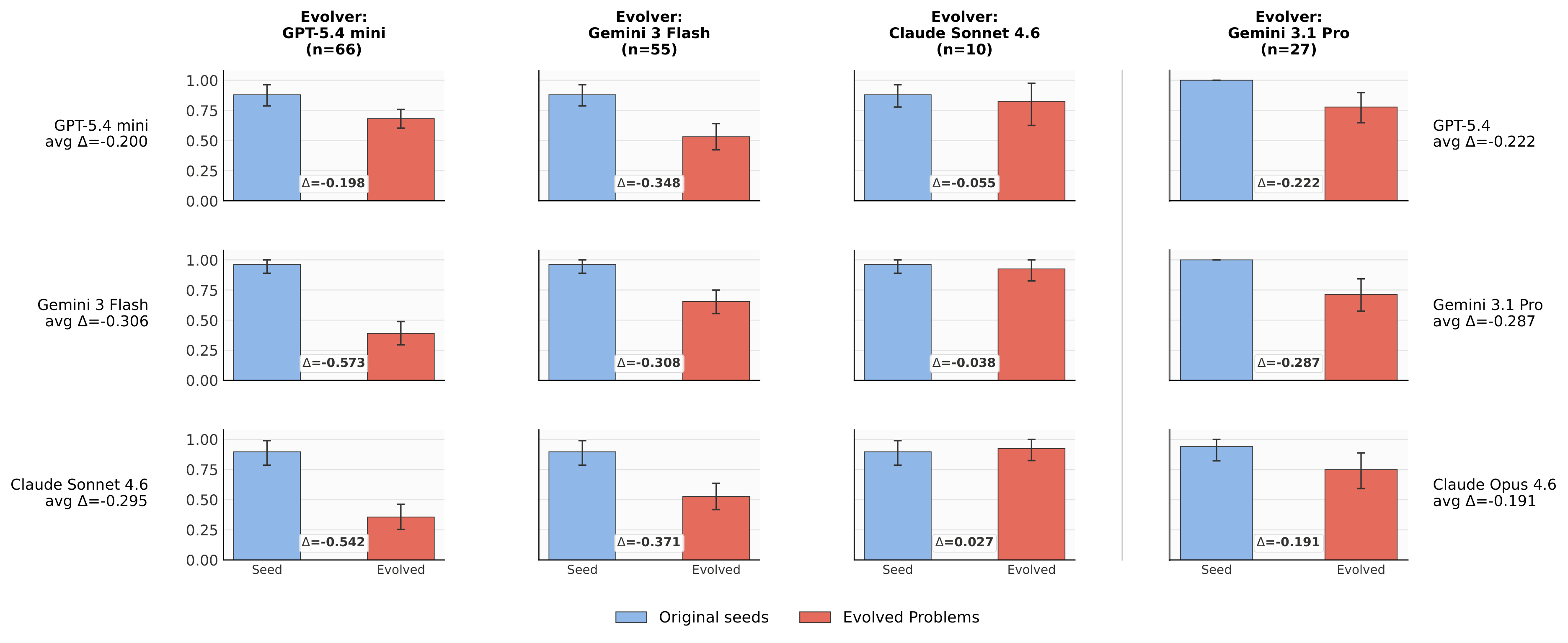
Triangulates the reference, a brute-force solver, and a statement-only oracle to catch inconsistencies; runs bounded repair; then accepts only if the target panel empirically fails more.
Memory
Local memory tracks each seed's lineage and error patterns; global memory enforces diversity across seeds — a family that already succeeded must clear a higher difficulty bar.